Probabilistic Graphical Model¶
Probabilistic graphical models (PGMs) are defined by \(\mathbb{G}\) and \(\mathbb{P}\), where \(\mathbb{G} = (\mathcal{V}, \mathcal{A})\) is the structure of the graphical model and \(\mathbb{P}\) is the parameters of the model. The nodes \(\mathcal{V} = \{V_0, V_1, ... , V_{n-1}\}\) in \(\mathbb{G}\) denote the random variables and the edges \(\mathcal{A}\) denote the probabilistic interactions among the variables. Typically, one random variable corresponds to one feature in the machine learning problems.
The advantages of PGMs lie in their clear and intuitive representation and rigorous mathematical foundation. They have found practical applications in broad domains like biomedical informatics, computer vision, environmental monitoring, risk management and transportation.
Note
FastPGM focuses specifically on discrete PGMs, where the random variables take on a finite set of discrete values.
Bayesian Network¶
Bayesian networks (BNs) are a pivotal type of PGMs. In a BN, \(\mathbb{G}\) is a directed acyclic graph (DAG), where each node in \(\mathcal{V}\) is associated with one variable and each edge in \(\mathcal{A}\) represents conditional dependencies among the two variables. \(V_j\) is called a parent of \(V_i\) if there exists a directed edge from \(V_j\) to \(V_i\) in \(\mathbb{G}\). We use \(\textbf{Par}(V_i)\) to denote the set of parent variables of \(V_i\).
The figure below illustrates the DAG \(\mathbb{G}\) of the Asia network with eight (0,1)-valued variables and eight edges. In this example, variable \(\sigma\) is the parent of variable \(\lambda\); the direct edge between them indicates whether smoking impacts the likelihood of a patient suffering from lung cancer. In BNs, the variables influencing \(V_i\) are exactly its parents \(\mathbf{Par}(V_i)\).
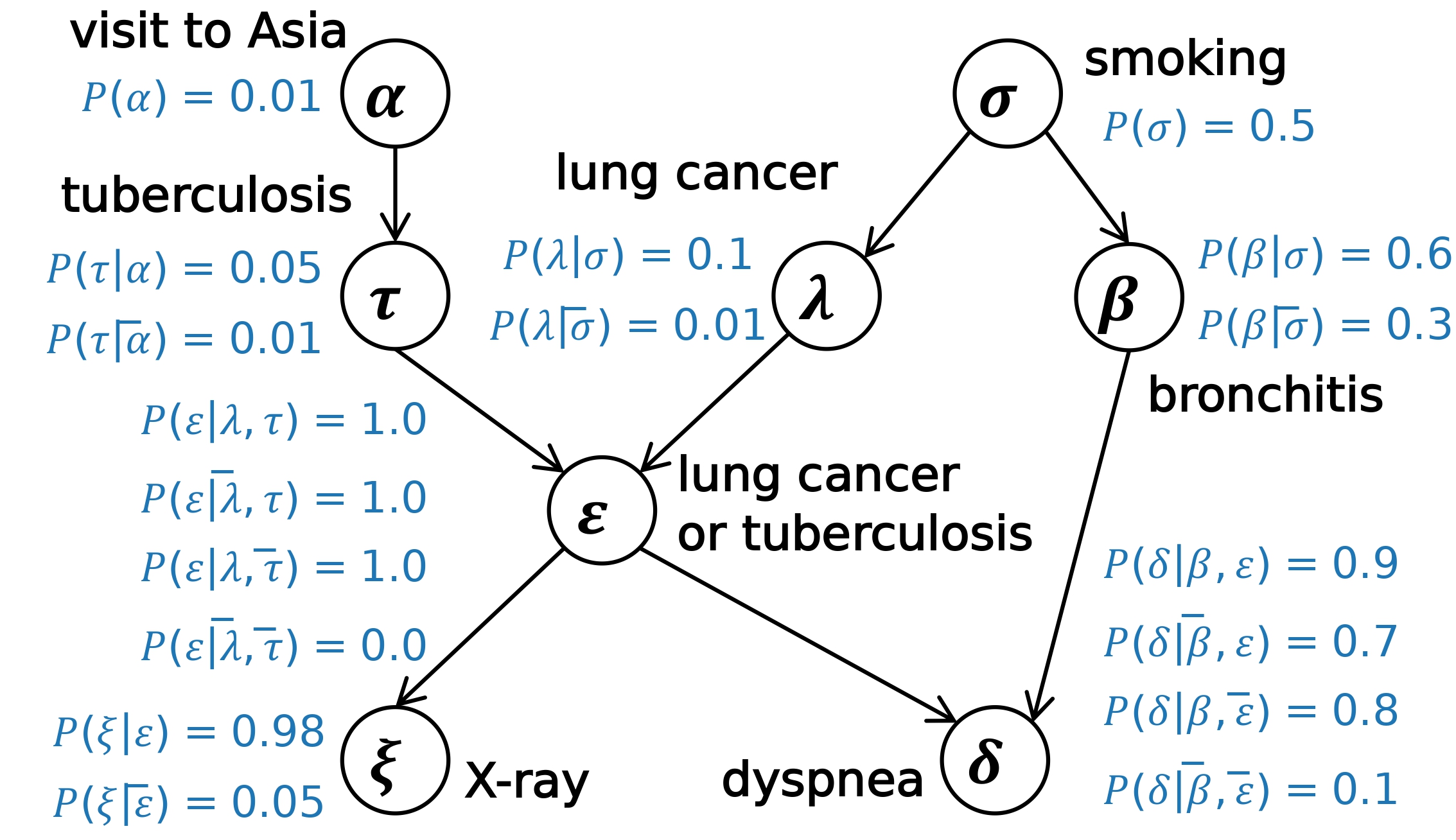
Fig. 1 An example Bayesian network named Asia. \(x\) is short for \(x=1\) while \(\overline{x}\) is short for \(x=0\), where \(x\) represents any variable in the BN.¶
The parameter set \(\mathbb{P}\) in a BN is a set of conditional probability distributions (CPDs). Each CPD describes the probability distribution of possible values of a variable given its possible parent configurations. For example, according to the CPD of \(\xi\), the probability of having an abnormal X-ray result is 0.98 for individuals diagnosed with lung cancer or tuberculosis and 0.05 for those without these conditions.
The overall joint probability of variables \(\mathcal{V}\) in a BN can be decomposed into the product of the local CPDs of each variable, and each local CPD depends only on a single variable \(V_i\) and its parents:
where \(n\) is the number of random variables, and \(P(V_i | \mathbf{Par}(V_i))\) is the CPD of \(V_i\).
Important
Key advantages of BNs: 1. BNs are represented by DAGs, where the directionality of edges captures causal relationships between variables. This feature makes BNs particularly advantageous in real-world complex scenarios where cause-and-effect relationships are prevalent. It also makes BNs suitable for areas where interpretability is crucial. 2. The flexibility of BNs in integrating prior knowledge is another critical advantage. The ability to incorporate domain-specific knowledge through prior distributions enhances the model’s robustness and performance.
Markov Random Field¶
Markov random fields (MRFs) are another subclass of PGMs. The major difference is that the structure \(\mathbb{G}\) of an MRF is an undirected graph. The absence of directed edges in the MRF implies that there is no inherent directionality in the relationships between variables; instead, the dependencies are symmetric and bidirectional.
The parameters \(\mathbb{P}\) of an MRF is a set of potential functions. Each potential function \(\phi_c(\mathcal{V}_c)\) defines a joint distribution over a set of variables \(\mathcal{V}_c \subseteq \mathcal{V}\), capturing the strength of the interaction of all the variables within \(\mathcal{V}_c\). A set \(\mathcal{V}_c\) is called a clique in MRFs, which is a fully connected subset, where every pair of nodes within the clique is connected by an edge. The figure below shows a simple MRF with four nodes and four edges. In this example, the cliques are the edges themselves.
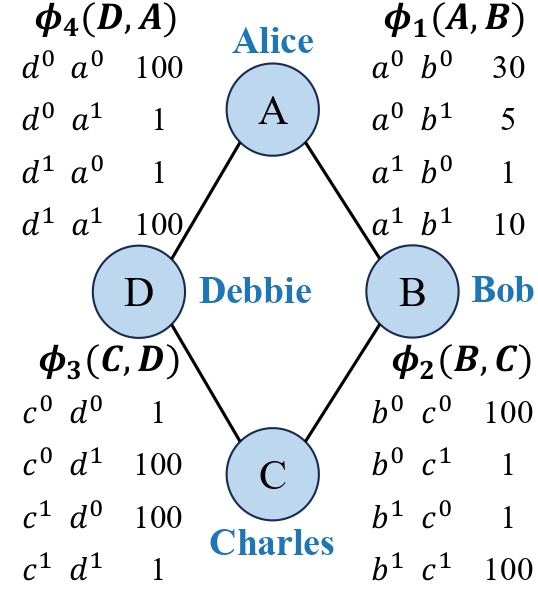
Fig. 2 A simple example Markov random field.¶
The overall joint distribution of an MRF can be factorized into a product of potential functions over the cliques of the graph:
where the term \(Z\) is the partition function, which is a normalization constant that ensures the joint probability distribution sums to one.
In fact, we can also get the CPD \(P(V_i | \mathbf{C}(V_i))\) of \(V_i\) via the potential functions:
We define the concept \(\mathbf{C}(V_i)\) as conditioning set, which means the variables influencing \(V_i\) in \(\mathbb{G}\). Recall that \(\mathbf{C}(V_i)\) is exactly \(\mathbf{Par}(V_i)\) in BNs; while in the context of MRFs, \(\mathbf{C}(V_i)\) is the Markov blanket of \(V_i\).
The core of the formula is to multiply all the potential functions that are related to \(\{V_i\} \cup \mathbf{C}(V_i)\) and sum over all possible values of \(V_i\). This computation allows for a unified perspective on BNs and MRFs, which is useful for the tasks on PGMs.
Important
The conditioning set \(\mathbf{C}(V_i)\) encompasses both the parents of \(V_i\) in the context of BNs and the Markov blanket of \(V_i\) in the context of MRFs, which is important for a unified perspective on PGMs.